With the explosion of the era of Big Data, companies now need to leverage all their available data in full to drive the decisions that will support their future growth. The scale and variety of this data now challenges Relational Databases and that is where Hadoop can really add benefit.
Hadoop development is hosted by the Apache OpenSource Community and all major technology companies have contributed to the codebase enabling Hadoop to leap ahead of proprietary solutions in a relatively short time period.
Hadoop’s main components are its file system (HDFS) that provides cheap and reliable data storage, and its MapReduce engine that provides high performance parallel data processing. In addition Hadoop is self managing and can easily handle hardware failures as well as scaling up or down its deployment without any change to the codebase.Hadoop installs on low cost commodity servers reducing the deployment cost.While first deployed by the main web properties Hadoop is now widely used across many sectors including entertainment, healthcare, government and market research.

In normal life , if we want to perform some computation job like searching 1 name from 100 Row table , we can do with low end hardware ( e.g. 1 GB RAM , 1 Core Processor).
Now suppose we need to find 1 name from 1 million records in quick time. Hum..mm it will take some time to search not exactly but it might take 1 hour to find out record in huge DB. To reduce time span we can increase hardware capacity of current hardware and we can again get good performance for output.
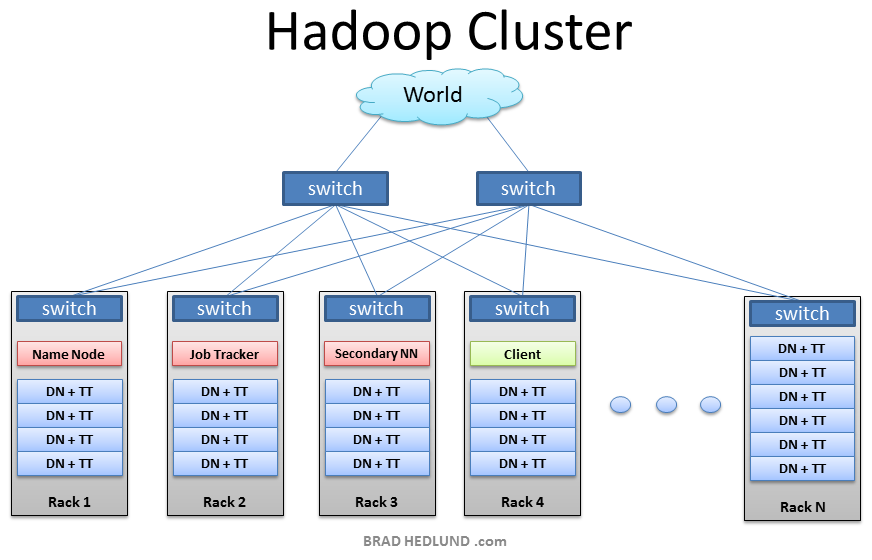
As you seen above We can solve the problem by increasing hardware capacity which we normally call's Vertical scaling. It means you can increase hardware as per your requirement. In this case there is one word come in mind as "Hardware specification". Like we can increase RAM of machine till some limit and we can't increase its capacity beyond some limit. Now suppose we have found that if we need query output in the few second then what we can do here ? Can we plan to purchase some expensive high performance hardware which will take less time.
As any developer want his code should get appreciation and used in large scale that time we can't add restriction to user that he need 30 GB RAM and 10 Core Processor to get best output. Now what we can do here to get good performance as vertical word come in picture we can use horizontal scaling :) . It means we can add another COMMODITY HARDWARE in the network and use it as COMPUTATIONAL NODE FOR PROCESSING.
It's any how better than purchasing single expensive hardware. The technical term to solve such problem we can call it as "distributed processing" where we can split the job for several machines and at the end we can summarize the output in required format.
Hadoop is excellent software framework for the "distributed processing" of large data sets across clusters of computers using simple programming models.It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures. While designing the framework main intention is to use COMMODITY Hardware instead of High End machines.
The underlying technology was invented by Google back in their earlier days so they could usefully index all the rich textural and structural information they were collecting, and then present meaningful and actionable results to users. There was nothing on the market that would let them do that, so they built their own platform. Google’s innovations were incorporated into Nutch, an open source project, and Hadoop was later spun-off from that. Yahoo has played a key role developing Hadoop for enterprise application
The Hadoop platform was designed to solve problems where you have a lot of data — perhaps a mixture of complex and structured data — and it doesn’t fit nicely into tables. It’s for situations where you want to run analytics that are deep and computationally extensive, like clustering and targeting. That’s exactly what Google was doing when it was indexing the web and examining user behavior to improve performance algorithms.

Hadoop: Assumptions
It is written with large clusters of computers in mind and is built around the following assumptions:
i) Hardware will fail.
ii) Processing will be run in batches. Thus there is an emphasis on high throughput as opposed to low latency.
iii) Applications that run on HDFS have large data sets. A typical file in HDFS is gigabytes to terabytes in size.
iv) It should provide high aggregate data bandwidth and scale to hundreds of nodes in a single cluster. It should support tens of millions of files in a single instance.
v) Applications need a write-once-read-many access model.
vi) Moving Computation is Cheaper than Moving Data.
vii) Portability is important.
What are the Hadoop's Eco System Component


6 comments:
Great blog for the database concepts and cloud based information. I came to know about this blog when attending hadoop online trainingin India. Thanks for well presented information about these technologies.
Nice blog....for more practice for Hadoop you may refer http://www.s4techno.com/lab-setup/
i just go through your article it’s very interesting time just pass away by reading your article looking for more updates. Thank you for sharing.
Best DevOps Training Institute
nice post.
salesforce training
hadoop training
mulesoft training
linux training
mulesoft training
web methods training
GREAT
Horizontal scaling is one of the fundamental concepts of Hadoop and refers to increasing the processing and storage capacity of a system by adding more machines (nodes) to a cluster rather than upgrading the hardware of a single machine. Unlike vertical scaling, which improves performance by adding more CPU, memory, or storage to one server, horizontal scaling distributes data and computational tasks across multiple low-cost commodity servers.Big Data Projects. Hadoop's distributed architecture, particularly the Hadoop Distributed File System (HDFS) and MapReduce framework, enables data to be stored and processed efficiently across many nodes, providing high availability, fault tolerance, and scalability.
Post a Comment