Imagine that you have coupons that you wanted to push to mobile customers that purchase a specific item. This is a customer facing system of engagement requires location data, purchase data, wallet data, and so on. You want to engage the mobile customer in real-time.
What you require is a very agile delivery system that is easily able to processes unstructured data. The system of engagement would need to be extremely dynamic.
A traditional database product would prefer more predictable, structured data. A relational database may require vertical and, sometimes horizontal expansion of servers, to expand as data or processing requirements grow.
An alternative, more cloud-friendly approach is to employ NoSQL.
NoSQL databases (either no-SQL or Not Only SQL) are currently a hot topic in some parts of computing
“NoSQL is a movement promoting a loosely defined class of non-relational data stores that break with a long history of relational
databases. These data stores may not require fixed table schemas,usually avoid join operations and typically scale horizontally.
Academics and papers typically refer to these databases as structured storage.”
What is NoSQL?
NoSQL is a popular name for a subset of structured storage software that is designed is optimized for high -
performance operations on large datasets. This optimization comes at the expense of strict ACID (atomicity, consistency, isolation,and durability) compliance and , as the name implies, native querying in the SQL syntax.
NoSQL software is easy for developers to use,horizontally scalable, and optimized for narrow workload definitions.
There are three major categories of NoSQL applications today:
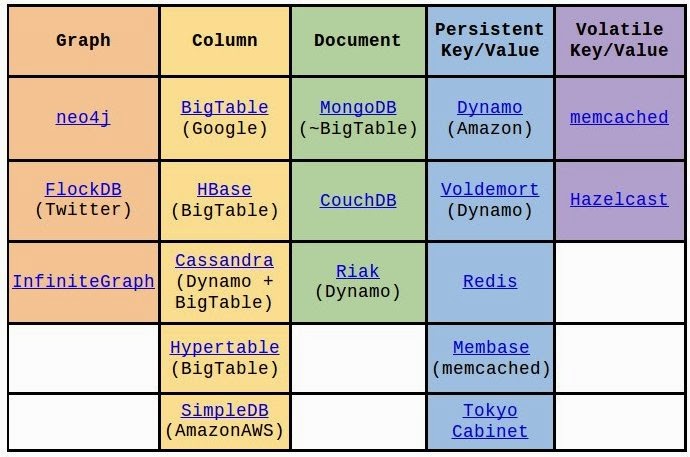
i) Key-value stores like Cassandra, Riak, and Project Voldemort?Graph databases like Neo4j, DEX,and Infinite Graph
ii) Document stores like MongoDB, eXist,and BaseX These NoSQL applications are either separate open source software(OSS) projectsor commercial closed-sourceprojects.
iii) The applications are written in different languages,they expose different interfaces,and they implement different optimizations
The load is able to easily grow by distributing itself over lots of ordinary, and cheap, Intel-based servers. A NoSQL database is exactly the type of database that can handle the sort of unstructured, messy and unpredictable data that our system of engagement requires.
NoSQL is a whole new way of thinking about a database. NoSQL is not a relational database. The reality is that a relational database model may not be the best solution for all situations. The easiest way to think of NoSQL, is that of a database which does not adhering to the traditional relational database management system (RDMS) structure. Sometimes you will also see it revered to as 'not only SQL'.
It is not built on tables and does not employ SQL to manipulate data. It also may not provide full ACID (atomicity, consistency, isolation, durability) guarantees, but still has a distributed and fault tolerant architecture.
The NoSQL taxonomy supports key-value stores, document store, BigTable, and graph database
NoSQL Advantage
1) Elastic scaling : RDBMS might not scale out easily on commodity clusters, but the new breed of NoSQL databases are designed to expand transparently to take advantage of new nodes, and they're usually designed with low-cost commodity hardware in mind.
For years, database administrators have relied on scale up -- buying bigger servers as database load increases -- rather than scale out -- distributing the database across multiple hosts as load increases. However, as transaction rates and availability requirements increase, and as databases move into the cloud or onto virtualized environments, the economic advantages of scaling out on commodity hardware become irresistible.
2) Big data : Just as transaction rates have grown out of recognition over the last decade, the volumes of data that are being stored also have increased massively. O'Reilly has cleverly called this the "industrial revolution of data." RDBMS capacity has been growing to match these increases, but as with transaction rates, the constraints of data volumes that can be practically managed by a single RDBMS are becoming intolerable for some enterprises. Today, the volumes of "big data" that can be handled by NoSQL systems, such as Hadoop, outstrip what can be handled by the biggest RDBMS.
3) Not much Admin Part : NoSQL databases are generally designed from the ground up to require less management: automatic repair, data distribution, and simpler data models lead to lower administration and tuning requirements
4) Economics : NoSQL databases typically use clusters of cheap commodity servers to manage the exploding data and transaction volumes, while RDBMS tends to rely on expensive proprietary servers and storage systems. The result is that the cost per gigabyte or transaction/second for NoSQL can be many times less than the cost for RDBMS, allowing you to store and process more data at a much lower price point.
5) Flexible data models : Change management is a big headache for large production RDBMS. Even minor changes to the data model of an RDBMS have to be carefully managed and may necessitate downtime or reduced service levels. NoSQL databases have far more relaxed -- or even nonexistent -- data model restrictions. NoSQL Key Value stores and document databases allow the application to store virtually any structure it wants in a data element. Even the more rigidly defined BigTable-based NoSQL databases (Cassandra, HBase) typically allow new columns to be created without too much fuss.The result is that application changes and database schema changes do not have to be managed as one complicated change unit. In theory, this will allow applications to iterate faster, though,clearly, there can be undesirable side effects if the application fails to manage data integrity.
Challenges of NoSQL
1) Maturity : RDBMS systems have been around for a long time. NoSQL advocates will argue that their advancing age is a sign of their obsolescence, but for most CIOs, the maturity of the RDBMS is reassuring. For the most part, RDBMS systems are stable and richly functional. In comparison, most NoSQL alternatives are in pre-production versions with many key features yet to be implemented. Living on the technological leading edge is an exciting prospect for many developers, but enterprises should approach it with extreme caution.
2) Support : Enterprises want the reassurance that if a key system fails, they will be able to get timely and competent support. All RDBMS vendors go to great lengths to provide a high level of enterprise support.
In contrast, most NoSQL systems are open source projects, and although there are usually one or more firms offering support for each NoSQL database, these companies often are small start-ups without the global reach, support resources, or credibility of an Oracle, Microsoft, or IBM.
3) Analytic and business intelligence :NoSQL databases have evolved to meet the scaling demands of modern Web 2.0 applications. Consequently, most of their feature set is oriented toward the demands of these applications. However, data in an application has value to the business that goes beyond the insert-read-update-delete cycle of a typical Web application. Businesses mine information in corporate databases to improve their efficiency and competitiveness, and business intelligence (BI) is a key IT issue for all medium to large companies.
NoSQL databases offer few facilities for ad-hoc query and analysis. Even a simple query requires significant programming expertise, and commonly used BI tools do not provide connectivity to NoSQL.
4) Expertise
There are literally millions of developers throughout the world, and in every business segment, who are familiar with RDBMS concepts and programming. In contrast, almost every NoSQL developer is in a learning mode. This situation will address naturally over time, but for now, it's far easier to find experienced RDBMS programmers or administrators than a NoSQL expert.
Right off the bat, NoSQL databases are unique because they are usually independent from Structured Query Language (SQL) found in relational databases. Relational databases all use SQL as the domain-specific language for ad hoc queries, while non-relational databases have no such standard query language, so they can use whatever they want. That can, if need be, include SQL.
NoSQL databases are designed to excel in speed and volume. To pull this off, NoSQL software will use techniques that can scare the crap out of relational database users — such as not promising that all data is consistent within a system all of the time.
That's a key result of using relational databases, because when you are conducting a financial transaction, such as buying something on Amazon, databases have to be very sure that one account is debited the same amount that another account is debited at the same time. Because so much of this back-and-forth read-write activity is needed in a single transaction, a relational database could never keep up with the speed and scaling necessary to make a company like Amazon work.
Go Big Or Go Home
Easier scalability is the first aspect highlighted by Wiederhold. NoSQL databases like Couchbase and 10Gen's MongoDB, he said, can be scaled up to handle much bigger data volumes with relative ease.
If your company suddenly finds itself deluged by overnight success, for example, with customers coming to your Web site by the droves, a relational database would have to be painstakingly replicated and re-partitioned in order to scale up to meet the new demand.
Wieder hold cited social and mobile gaming vendors as the big example of this kind of situation. An endorsement or a few well-timed tweets could spin up semi-dormant gaming servers and get them to capacity in mere hours. Because of the distributed nature of non-relational databases, to scale NoSQL all you need to do is add machines to the cluster to meet demand.
Performance / scaling
Performance is another way that NoSQL databases can excel. First, every time you add a new server to a NoSQL database cluster, there is performance scaling by virtue of the fact that you're throwing another processor into the equation.
Beyond the scaling advantages, the very architecture of NoSQL tools aids performance. If a relational database had tens or even hundreds of thousands of tables, data processing would generate far more locks on that data, and greatly degrade the performance of the database.
Because NoSQL databases have weaker data consistency models, they can trade off consistency for efficiency. In Wiederhold's social gaming example, if a user updated his or her profile, there's no real degradation of game performance if that profile's new info isn't updated across the entire database instantly. This means that resources can be dedicated to other things, like tracking down that that's about smack you around in-game.
What is CAP about?
The (CAP) theorem (Consistency, Availability and Partitioning tolerance) was given by Eric Brewer, a professor at the University of California, Berkeley and one of the founders of Google, in 2001 in the keynote of Principles of Distributed Computing

Let’s first give definitions to these 3 terms:
Consistency: A service that is consistent should follow the rule of ordering for updates that spread across all replicas in a cluster – “what you write is what you read”, regardless of location. For example, Client A writes 1 then 2 to location X, Client B cannot read 2 followed by 1. This rule has another name “Strong consistency”.
Availability: A service should be available. There should be a guarantee that every request receives a response about whether it was successful or failed. If the system is not available it can be still consistent. However, consistency and availability cannot be achieved at the same time. This means that one has two choices on what to leave. Relaxing consistency will allow the system to remain highly available under the partitioning conditions (see next definition) and strong consistency means that under certain conditions the system will not be available.
Partition tolerance: The system continues to operate despite arbitrary message loss or failure of part of the system. A simple example, when we have a cluster of N replicated nodes and for some reason a network is unavailable among some number of nodes (e.g. a network cable got chopped). This leads to inability to synchronize data. Thus, only some part of the system doesn’t work, the other one does. If you have a partition in your network, you lose either consistency (because you allow updates to both sides of the partition) or you lose availability (because you detect the error and shut down the system until the error condition is resolved).
A simple meaning of this theorem is “It is impossible for a protocol to guarantee both consistency and availability in a partition prone distributed system”. Please find below information in details .
The popular understanding of Eric Brewer's CAP Theorem is that in distributed systems it is only possible to support two out of three desired properties: consistency, availability and partition tolerance. The 'two out of three' explanation of CAP Theorem has been used in recent years to explain and justify the emergence of NoSQL databases that relax consistency in favour of high availability. It has likewise been used to question the validity of claims that NewSQL databases are able to deliver both highly available distributed architecture and support ACID transactions.
We are just talking about principle but how we can achieve
Availability is achieved by replicating the data across different machines
Consistency is achieved by updating several nodes before allowing further reads
Total partitioning, meaning failure of part of the system is rare. However, we could look at a delay, a latency, of the update between nodes, as a temporary partitioning. It will then cause a temporary decision between A and C:
On systems that allow reads before updating all the nodes, we will get high Availability
On systems that lock all the nodes before allowing reads, we will get Consistency

What you require is a very agile delivery system that is easily able to processes unstructured data. The system of engagement would need to be extremely dynamic.
A traditional database product would prefer more predictable, structured data. A relational database may require vertical and, sometimes horizontal expansion of servers, to expand as data or processing requirements grow.
An alternative, more cloud-friendly approach is to employ NoSQL.
NoSQL databases (either no-SQL or Not Only SQL) are currently a hot topic in some parts of computing
“NoSQL is a movement promoting a loosely defined class of non-relational data stores that break with a long history of relational
databases. These data stores may not require fixed table schemas,usually avoid join operations and typically scale horizontally.
Academics and papers typically refer to these databases as structured storage.”
What is NoSQL?
NoSQL is a popular name for a subset of structured storage software that is designed is optimized for high -
performance operations on large datasets. This optimization comes at the expense of strict ACID (atomicity, consistency, isolation,and durability) compliance and , as the name implies, native querying in the SQL syntax.
NoSQL software is easy for developers to use,horizontally scalable, and optimized for narrow workload definitions.
There are three major categories of NoSQL applications today:
i) Key-value stores like Cassandra, Riak, and Project Voldemort?Graph databases like Neo4j, DEX,and Infinite Graph
ii) Document stores like MongoDB, eXist,and BaseX These NoSQL applications are either separate open source software(OSS) projectsor commercial closed-sourceprojects.
iii) The applications are written in different languages,they expose different interfaces,and they implement different optimizations
The load is able to easily grow by distributing itself over lots of ordinary, and cheap, Intel-based servers. A NoSQL database is exactly the type of database that can handle the sort of unstructured, messy and unpredictable data that our system of engagement requires.
NoSQL is a whole new way of thinking about a database. NoSQL is not a relational database. The reality is that a relational database model may not be the best solution for all situations. The easiest way to think of NoSQL, is that of a database which does not adhering to the traditional relational database management system (RDMS) structure. Sometimes you will also see it revered to as 'not only SQL'.
It is not built on tables and does not employ SQL to manipulate data. It also may not provide full ACID (atomicity, consistency, isolation, durability) guarantees, but still has a distributed and fault tolerant architecture.
The NoSQL taxonomy supports key-value stores, document store, BigTable, and graph database
NoSQL Advantage
1) Elastic scaling : RDBMS might not scale out easily on commodity clusters, but the new breed of NoSQL databases are designed to expand transparently to take advantage of new nodes, and they're usually designed with low-cost commodity hardware in mind.
For years, database administrators have relied on scale up -- buying bigger servers as database load increases -- rather than scale out -- distributing the database across multiple hosts as load increases. However, as transaction rates and availability requirements increase, and as databases move into the cloud or onto virtualized environments, the economic advantages of scaling out on commodity hardware become irresistible.
2) Big data : Just as transaction rates have grown out of recognition over the last decade, the volumes of data that are being stored also have increased massively. O'Reilly has cleverly called this the "industrial revolution of data." RDBMS capacity has been growing to match these increases, but as with transaction rates, the constraints of data volumes that can be practically managed by a single RDBMS are becoming intolerable for some enterprises. Today, the volumes of "big data" that can be handled by NoSQL systems, such as Hadoop, outstrip what can be handled by the biggest RDBMS.
3) Not much Admin Part : NoSQL databases are generally designed from the ground up to require less management: automatic repair, data distribution, and simpler data models lead to lower administration and tuning requirements
4) Economics : NoSQL databases typically use clusters of cheap commodity servers to manage the exploding data and transaction volumes, while RDBMS tends to rely on expensive proprietary servers and storage systems. The result is that the cost per gigabyte or transaction/second for NoSQL can be many times less than the cost for RDBMS, allowing you to store and process more data at a much lower price point.
5) Flexible data models : Change management is a big headache for large production RDBMS. Even minor changes to the data model of an RDBMS have to be carefully managed and may necessitate downtime or reduced service levels. NoSQL databases have far more relaxed -- or even nonexistent -- data model restrictions. NoSQL Key Value stores and document databases allow the application to store virtually any structure it wants in a data element. Even the more rigidly defined BigTable-based NoSQL databases (Cassandra, HBase) typically allow new columns to be created without too much fuss.The result is that application changes and database schema changes do not have to be managed as one complicated change unit. In theory, this will allow applications to iterate faster, though,clearly, there can be undesirable side effects if the application fails to manage data integrity.
Challenges of NoSQL
1) Maturity : RDBMS systems have been around for a long time. NoSQL advocates will argue that their advancing age is a sign of their obsolescence, but for most CIOs, the maturity of the RDBMS is reassuring. For the most part, RDBMS systems are stable and richly functional. In comparison, most NoSQL alternatives are in pre-production versions with many key features yet to be implemented. Living on the technological leading edge is an exciting prospect for many developers, but enterprises should approach it with extreme caution.
2) Support : Enterprises want the reassurance that if a key system fails, they will be able to get timely and competent support. All RDBMS vendors go to great lengths to provide a high level of enterprise support.
In contrast, most NoSQL systems are open source projects, and although there are usually one or more firms offering support for each NoSQL database, these companies often are small start-ups without the global reach, support resources, or credibility of an Oracle, Microsoft, or IBM.
3) Analytic and business intelligence :NoSQL databases have evolved to meet the scaling demands of modern Web 2.0 applications. Consequently, most of their feature set is oriented toward the demands of these applications. However, data in an application has value to the business that goes beyond the insert-read-update-delete cycle of a typical Web application. Businesses mine information in corporate databases to improve their efficiency and competitiveness, and business intelligence (BI) is a key IT issue for all medium to large companies.
NoSQL databases offer few facilities for ad-hoc query and analysis. Even a simple query requires significant programming expertise, and commonly used BI tools do not provide connectivity to NoSQL.
4) Expertise
There are literally millions of developers throughout the world, and in every business segment, who are familiar with RDBMS concepts and programming. In contrast, almost every NoSQL developer is in a learning mode. This situation will address naturally over time, but for now, it's far easier to find experienced RDBMS programmers or administrators than a NoSQL expert.
Right off the bat, NoSQL databases are unique because they are usually independent from Structured Query Language (SQL) found in relational databases. Relational databases all use SQL as the domain-specific language for ad hoc queries, while non-relational databases have no such standard query language, so they can use whatever they want. That can, if need be, include SQL.
NoSQL databases are designed to excel in speed and volume. To pull this off, NoSQL software will use techniques that can scare the crap out of relational database users — such as not promising that all data is consistent within a system all of the time.
That's a key result of using relational databases, because when you are conducting a financial transaction, such as buying something on Amazon, databases have to be very sure that one account is debited the same amount that another account is debited at the same time. Because so much of this back-and-forth read-write activity is needed in a single transaction, a relational database could never keep up with the speed and scaling necessary to make a company like Amazon work.
Go Big Or Go Home
Easier scalability is the first aspect highlighted by Wiederhold. NoSQL databases like Couchbase and 10Gen's MongoDB, he said, can be scaled up to handle much bigger data volumes with relative ease.
If your company suddenly finds itself deluged by overnight success, for example, with customers coming to your Web site by the droves, a relational database would have to be painstakingly replicated and re-partitioned in order to scale up to meet the new demand.
Wieder hold cited social and mobile gaming vendors as the big example of this kind of situation. An endorsement or a few well-timed tweets could spin up semi-dormant gaming servers and get them to capacity in mere hours. Because of the distributed nature of non-relational databases, to scale NoSQL all you need to do is add machines to the cluster to meet demand.
Performance / scaling
Performance is another way that NoSQL databases can excel. First, every time you add a new server to a NoSQL database cluster, there is performance scaling by virtue of the fact that you're throwing another processor into the equation.
Beyond the scaling advantages, the very architecture of NoSQL tools aids performance. If a relational database had tens or even hundreds of thousands of tables, data processing would generate far more locks on that data, and greatly degrade the performance of the database.
Because NoSQL databases have weaker data consistency models, they can trade off consistency for efficiency. In Wiederhold's social gaming example, if a user updated his or her profile, there's no real degradation of game performance if that profile's new info isn't updated across the entire database instantly. This means that resources can be dedicated to other things, like tracking down that that's about smack you around in-game.
What is CAP about?
The (CAP) theorem (Consistency, Availability and Partitioning tolerance) was given by Eric Brewer, a professor at the University of California, Berkeley and one of the founders of Google, in 2001 in the keynote of Principles of Distributed Computing
Let’s first give definitions to these 3 terms:
Consistency: A service that is consistent should follow the rule of ordering for updates that spread across all replicas in a cluster – “what you write is what you read”, regardless of location. For example, Client A writes 1 then 2 to location X, Client B cannot read 2 followed by 1. This rule has another name “Strong consistency”.
Availability: A service should be available. There should be a guarantee that every request receives a response about whether it was successful or failed. If the system is not available it can be still consistent. However, consistency and availability cannot be achieved at the same time. This means that one has two choices on what to leave. Relaxing consistency will allow the system to remain highly available under the partitioning conditions (see next definition) and strong consistency means that under certain conditions the system will not be available.
Partition tolerance: The system continues to operate despite arbitrary message loss or failure of part of the system. A simple example, when we have a cluster of N replicated nodes and for some reason a network is unavailable among some number of nodes (e.g. a network cable got chopped). This leads to inability to synchronize data. Thus, only some part of the system doesn’t work, the other one does. If you have a partition in your network, you lose either consistency (because you allow updates to both sides of the partition) or you lose availability (because you detect the error and shut down the system until the error condition is resolved).
A simple meaning of this theorem is “It is impossible for a protocol to guarantee both consistency and availability in a partition prone distributed system”. Please find below information in details .
The popular understanding of Eric Brewer's CAP Theorem is that in distributed systems it is only possible to support two out of three desired properties: consistency, availability and partition tolerance. The 'two out of three' explanation of CAP Theorem has been used in recent years to explain and justify the emergence of NoSQL databases that relax consistency in favour of high availability. It has likewise been used to question the validity of claims that NewSQL databases are able to deliver both highly available distributed architecture and support ACID transactions.
 |
| We can't achieve All 3 characteristic in one |
We are just talking about principle but how we can achieve
Availability is achieved by replicating the data across different machines
Consistency is achieved by updating several nodes before allowing further reads
Total partitioning, meaning failure of part of the system is rare. However, we could look at a delay, a latency, of the update between nodes, as a temporary partitioning. It will then cause a temporary decision between A and C:
On systems that allow reads before updating all the nodes, we will get high Availability
On systems that lock all the nodes before allowing reads, we will get Consistency
1 comment:
Great inspiration today!!! thanks for your blog.
Ethical Hacking Course in Chennai
Hacking Course in Chennai
Python Training in Chennai
RPA Training in Chennai
Post a Comment