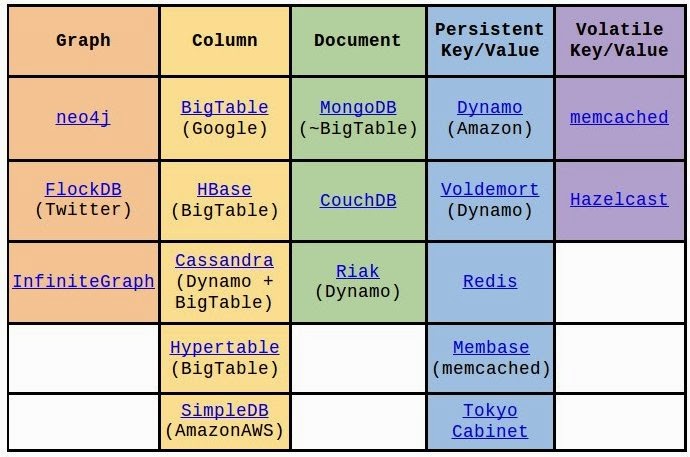
MongoDB (from "humongous") is an open-source document databaseis the leading NoSQL database which provide document database data structure for storing/retriving the elements. MongoDB provides high performance, high availability and easy scalability.
MongoDB is made up of databases which contain collections. A collection is made up of documents . Each document is made up of fields .Collections can be indexed , which improves lookup and sorting performance. Finally, when we get data from MongoDB we do so through a cursor whose actual execution is delayed until necessary.
To get started, there are six simple concepts we need to understand.
1) MongoDB has the same concept of a database with which you are likely already familiar (schema in Oracle/db2). Within a MongoDB instance you can have zero or more databases, each acting as high-level containers for everything else
2) A database can have zero or more collections . A collection shares enough in common with a traditional table that you can safely think of the two as the same thing.
3) Collections are made up of zero or more documents . Again, a document can safely be thought of as a row.
4) A document is made up of one or more fields , which you can probably guess are a lot like columns.
5) Indexes in MongoDB function much like their RDBMS counterparts.
6) Cursors are different than the other five concepts but they are important enough, and often overlooked, that I think they are worthy of their own discussion. The important thing to understand about cursors is that when you ask MongoDB for data, it returns a cursor, which we can do things to, such as counting or skipping ahead, without actually pulling down data.
Core Concept for Storing elements
The core difference comes from the fact that relational databases define columns at the table level whereas a document-oriented database defines its fields at the document level. That is to say that each document within a collection can have its own unique set of fields As such, a collection is a dumbed down container in comparison to a table , while a document has a lot more information than a row Ultimately, the point is that a collection isn’t strict about what goes in it (it’s schema-less). Fields are tracked with each individual document.
 |
| How MongoDB Data Looks like |
To get started, there are six simple concepts we need to understand.
1) MongoDB has the same concept of a database with which you are likely already familiar (schema in Oracle/db2). Within a MongoDB instance you can have zero or more databases, each acting as high-level containers for everything else
2) A database can have zero or more collections . A collection shares enough in common with a traditional table that you can safely think of the two as the same thing.
3) Collections are made up of zero or more documents . Again, a document can safely be thought of as a row.
4) A document is made up of one or more fields , which you can probably guess are a lot like columns.
5) Indexes in MongoDB function much like their RDBMS counterparts.
6) Cursors are different than the other five concepts but they are important enough, and often overlooked, that I think they are worthy of their own discussion. The important thing to understand about cursors is that when you ask MongoDB for data, it returns a cursor, which we can do things to, such as counting or skipping ahead, without actually pulling down data.
Core Concept for Storing elements
The core difference comes from the fact that relational databases define columns at the table level whereas a document-oriented database defines its fields at the document level. That is to say that each document within a collection can have its own unique set of fields As such, a collection is a dumbed down container in comparison to a table , while a document has a lot more information than a row Ultimately, the point is that a collection isn’t strict about what goes in it (it’s schema-less). Fields are tracked with each individual document.
 |
| RDBMS / Mongo DB Design |